Traditional Definition of SRE
Site Reliability Engineering or "SRE" is a relatively new title and position that had its roots in Google and made its way to the broader software community in 2003. It has since matured and evolved, many times taking on different meanings depending on who you talk to, or where you go. This can lead to some confusion, as well as blurred lines between SRE and Devops. What I hope to share is my experience and personal opinion on what the "traditional" intent was for SRE, and in my experience how that compares to what companies are doing now and what the term and role SRE describe to me.
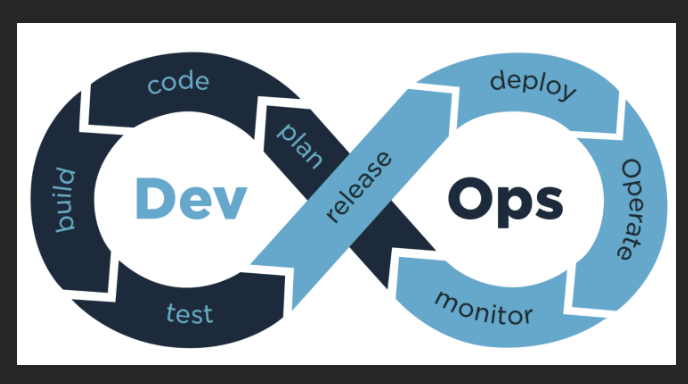
In the traditional sense, and what Google had in mind when they created the role of SRE, DevOps was to be thought of as a philosophy, and SRE as a prescriptive way of accomplishing that philosophy; implementing the developer mindset, workflows, tools, etc...and applying them to the operations world. Under this definition, DevOps is like "What to do", and SRE is like "How to do".
However, as mentioned this "traditional" definition of SRE can be blurred with DevOps, and can vary depending on where you go and who you talk to. Since its inception, SRE has evolved to encompass many different meanings and responsibilities. But, the core principals and reason for its creation, many of which overlap with DevOps, still hold true - which is to solve the pain point of infrastructure that you continually roll changes out to. At its core, the objective is to create reliable, redundant, fault tolerant, immutable infrastructure using infrastructure as code and a set of guiding principals, standards, and workflows. This of course with the understanding of working closely with both developers, and operations.
And SRE mentality is that "once software is stabilized and deployed in production that it needs much less attention" is wrong. We want systems that are automatic, not just automated. 50% of an SREs time should be dedicated to Ops work. That 50% is the cap according to Google. The other 50% should be focused on development work and making the application more reliable, as well as reducing toil by automating repetitive development tasks. That percentage should decrease overtime, as the Ops work that an SRE does should make the application run and repair itself on its own. The amount of SRE is needed to run, repair and monitor a system scales sub-linearly with a system.
SRE Foundational Practices
Forty to ninety percent of business costs come after birth or after the creation of something, but most of the effort is put into before something is created. However, what happens after? That is where SRE comes in.
Site Reliability Engineers are Software Engineers who's focus is on that forty to ninety percent, and are cross functionally Software Engineers, but geared towards business objectives, goals, and saving costs. As such, an SRE's main focus is on the Production environment, and most importantly (as the name suggests) system reliability and being able to able to shape the data and protect it from failure.
- Observability - which is monitoring, is something an SRE needs to know a lot about because redundancy helps keep a system reliable.
- Observability vs Monitoring - observability is how much minoring you have in place, or your level/ scope of coverage, monitoring is the tools you use to visualize and alert to have observability.
- Redundancy - essentially a way to back up data - like having a leader / follower. So we would want a cluster of DB where one DB will take in the writes and then communicate them to the other nodes in the cluster.
Defining Availability Through SLA's, SLO's, and SLI's
Being that SREs are geared towards business objectives and goals, and the prerequisite to success is Availability, it falls under the responsibility of SRE to define the Availability of the services the business provides. A system that is unavailable cannot perform its function and will fail by default.
Defining Availability can look like the following:This is done thorough what are called SLIs (Service Level Indicators), SLOs (Service Level Objectives), and SLAs (Service Level Agreements).
SRE Practices
Broadly speaking, in the "traditional" definition, DevOps describes what needs to be done to unify software development and operations. Whereas the "traditional" intent with SRE prescribes how this can be done. While SRE culture prioritizes reliability over the speed of change, DevOps instead accentuates agility across all stages of the product development cycle. However, both approaches try to find a balance between two poles and can complement each other in terms of methods, practices, and solutions

The Four Golden Signals
The four golden signals of monitoring are latency, traffic, errors, and saturation. If you can only measure four metrics of your user-facing system, focus on these four.
The time it takes to service a request. It’s important to distinguish between the latency of successful requests and the latency of failed requests. For example, an HTTP 500 error triggered due to loss of connection to a database or other critical backend might be served very quickly; however, as an HTTP 500 error indicates a failed request, factoring 500s into your overall latency might result in misleading calculations. On the other hand, a slow error is even worse than a fast error! Therefore, it’s important to track error latency, as opposed to just filtering out errors.
A measure of how much demand is being placed on your system, measured in a high-level system-specific metric. For a web service, this measurement is usually HTTP requests per second, perhaps broken out by the nature of the requests (e.g., static versus dynamic content). For an audio streaming system, this measurement might focus on network I/O rate or concurrent sessions. For a key-value storage system, this measurement might be transactions and retrievals per second.
The rate of requests that fail, either explicitly (e.g., HTTP 500s), implicitly (for example, an HTTP 200 success response, but coupled with the wrong content), or by policy (for example, "If you committed to one-second response times, any request over one second is an error"). Where protocol response codes are insufficient to express all failure conditions, secondary (internal) protocols may be necessary to track partial failure modes. Monitoring these cases can be drastically different: catching HTTP 500s at your load balancer can do a decent job of catching all completely failed requests, while only end-to-end system tests can detect that you’re serving the wrong content.
How "full" your service is. A measure of your system fraction, emphasizing the resources that are most constrained (e.g., in a memory-constrained system, show memory; in an I/O-constrained system, show I/O). Note that many systems degrade in performance before they achieve 100% utilization, so having a utilization target is essential.
In complex systems, saturation can be supplemented with higher-level load measurement: can your service properly handle double the traffic, handle only 10% more traffic, or handle even less traffic than it currently receives? For very simple services that have no parameters that alter the complexity of the request (e.g., "Give me a nonce" or "I need a globally unique monotonic integer") that rarely change configuration, a static value from a load test might be adequate. As discussed in the previous paragraph, however, most services need to use indirect signals like CPU utilization or network bandwidth that have a known upper bound. Latency increases are often a leading indicator of saturation. Measuring your 99th percentile response time over some small window (e.g., one minute) can give a very early signal of saturation. Finally, saturation is also concerned with predictions of impending saturation, such as "It looks like your database will fill its hard drive in 4 hours." If you measure all four golden signals and page a human when one signal is problematic (or, in the case of saturation, nearly problematic), your service will be at least decently covered by monitoring.
SRE Principals
In addition to the concepts and principals above, the general mindset of an SRE when working on any project always has these fundamental propositions in mind:
The primary focus of SRE is system reliability, which is considered the most fundamental feature of any product.
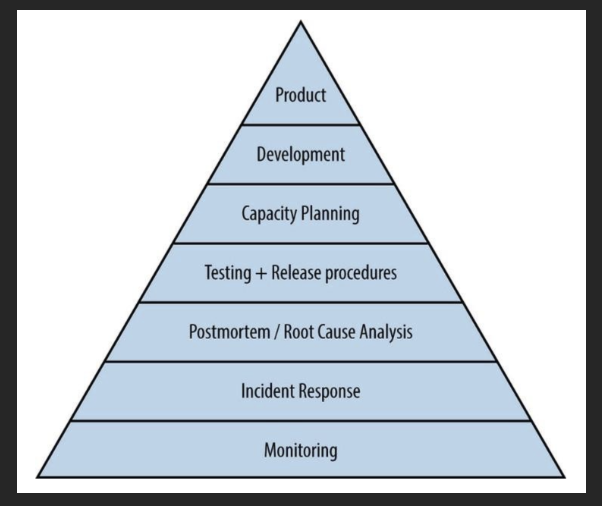
The pyramid below illustrates elements contributing to the reliability, from the most basic (monitoring) to the most advanced (reliable product launches).
DevOps Pillars and SRE Practices




DevOps vs SRE
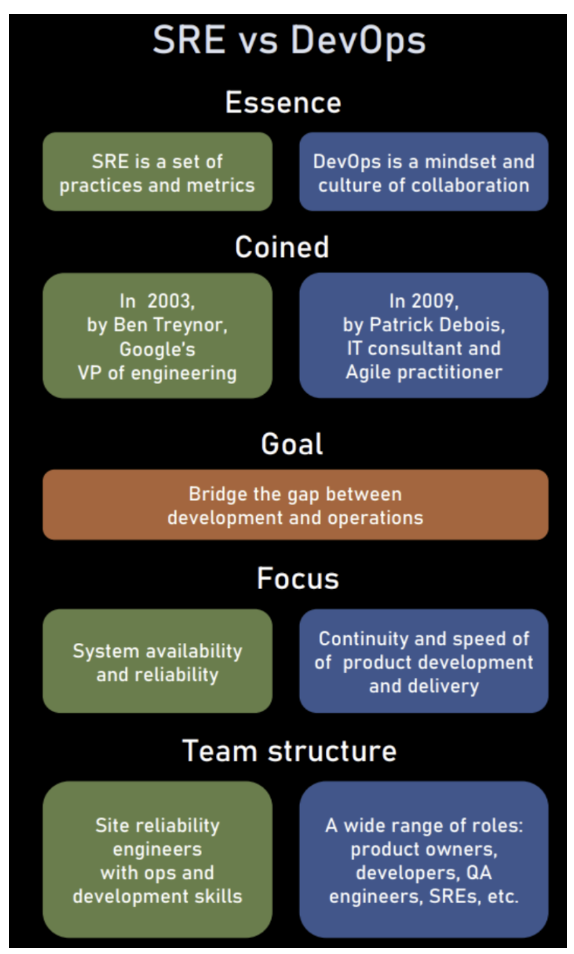
As mentioned previously, the lines can be blurred between the two. But, the DevOps core principles, like: involvement of the IT function in each step of a Systems design and development, heavy reliance on automation versus human effort, the application of development skills and tools to operations tasks, are consistent with many of SRE principles and practices. So at it’s fundamental level, one could view DevOps as a generalization of several core SRE principles to a wide range of organizations, management structures, and personnel. One could equivalently view SRE as a specific implementation of DevOps with some idiosyncratic extensions.
Written: February 24, 2024