What Is MLOps
At the heart of MLOps is the continuous improvement of all business activity. MLOps is a compound of Machine Learning (ML) and Operations (Ops). It is the process and practices for designing, building, enabling, and supporting the efficient deployment of ML models in production to continuously improve business activity. Similar to DevOps, MLOps is based on automation, agility, and collaboration to improve quality. Also similar to DevOps, MLOps also supports CI/CD, in which MLOps aims to standardize a deployment and management of ML models alongside the operationalization of the ML pipeline. "It supports the release, activation, monitoring, performance tracking, management, reuse, maintenance, and governance of ML artifacts."
Without DevOps, you cannot do MLOps. DevOps is a foundational building block for doing MLOps, and there is no substitute. DevOps is a methodology for releasing software in an agile manner; consistently improving the quality of both business outcomes and the software itself. A good DevOps Engineer is an expert in their domain, and has detailed knowledge of how to build software and deploy it in a high-quality and repeatable manner. This is arguably one of the biggest challenges for experts in Data Science to transition to MLOps; is a lack of experience doing DevOps. There is no substitute for experience, however, and many Data Science practitioners and Machine Learning researchers struggle building and deploying software with the DevOps methodology, as they do not posess the foundational knowledge and experience necessary to be considered an expert at MLOps.
There are a apparent differences between traditional DevOps and MLOps. One clear difference is a concept of data drift; when a model trains on data, it can gradually lose usefulness as the underlying data changes. That is just one example of many, but the takeaway is that DevOps is a necessary foundation for MLOps. Howeever, MLOps additional requirements (like data drift) don't appear in traditional DevOps. Ultimately, MLOps requires a business and production first mindset. The purpose of Machine Learning is to accelerate business value, and this means the teams building solutions must be agile in their approach to solving Machine Learning problems.
Machine Learning Pipelines
ML models can help organizations to spot opportunities and risks, improve their business strategy, and deliver better customer experience. But gathering and processing data for ML models, using it to train and test the models, and finally operationalizing machine learning, can take a long time. Companies want their data science teams to speed up the process so they can deliver valuable business predictions faster.
That’s where ML pipelines come in. By automating workflows with machine learning pipeline monitoring, ML pipelines bring you to operationalizing machine learning models sooner. As well as cutting down on the time it takes to produce a new ML model, machine learning pipeline orchestration also helps you improve the quality of your machine learning models. We call it a pipeline, but actual pipelines are one-way and one-time only, which isn’t the case for ML pipelines.
Through the principles of CI/CD, ML pipelines increase the accuracy of ML models and raise the quality of your algorithms. Data scientists in every vertical use automated ML pipelines to improve their ML models and speed up development and operationalization. A CI/CD pipeline for machine learning also helps a small data science team punch above its weight, as pipelines democratize access to ML models so that even small companies can apply machine learning to make better data-driven business decisions.
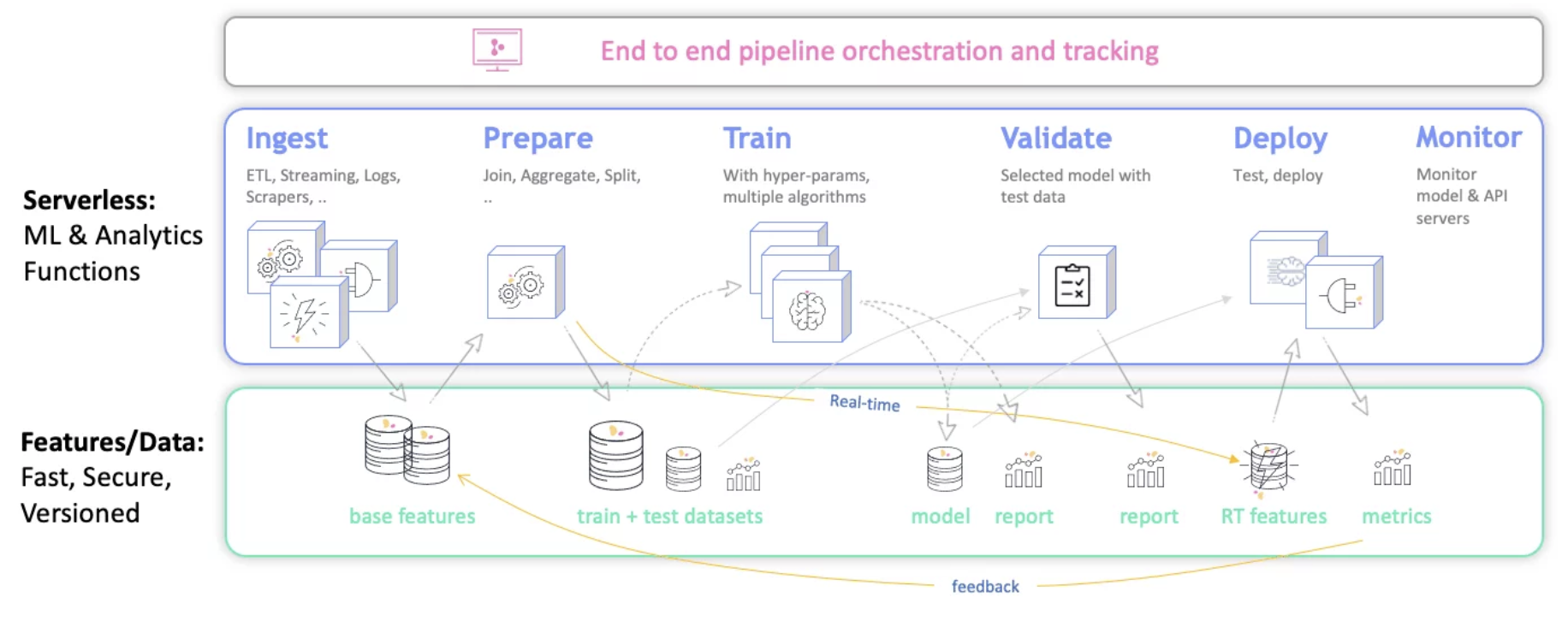
- Model Training - The process of applying the machine learning algorithm on training data to train an ML model. It also includes feature engineering and the hyperparameter tuning for the model training activity.
- Model Evaluation - Validating the trained model to ensure it meets original codified objectives before serving the ML model in production to the end-user.
- Model Testing - Performing the final “Model Acceptance Test” by using the hold backtest dataset.
- Model Packaging - The process of exporting the final ML model into a specific format (e.g. PMML, PFA, or ONNX), which describes the model, in order to be consumed by the business application.
- Model Serving - The process of addressing the ML model artifact in a production environment.
- Model Performance Monitoring - The process of observing the ML model performance based on live and previously unseen data, such as prediction or recommendation. In particular, we are interested in ML-specific signals, such as prediction deviation from previous model performance. These signals might be used as triggers for model re-training.
Machine Learning Technologies and Tools
- Kubeflow
- Seldon
- (GCP) VertexAI
- (AWS) SageMaker
- Databricks
- Airflow
- MLFlow
- AutoML
- MLRun
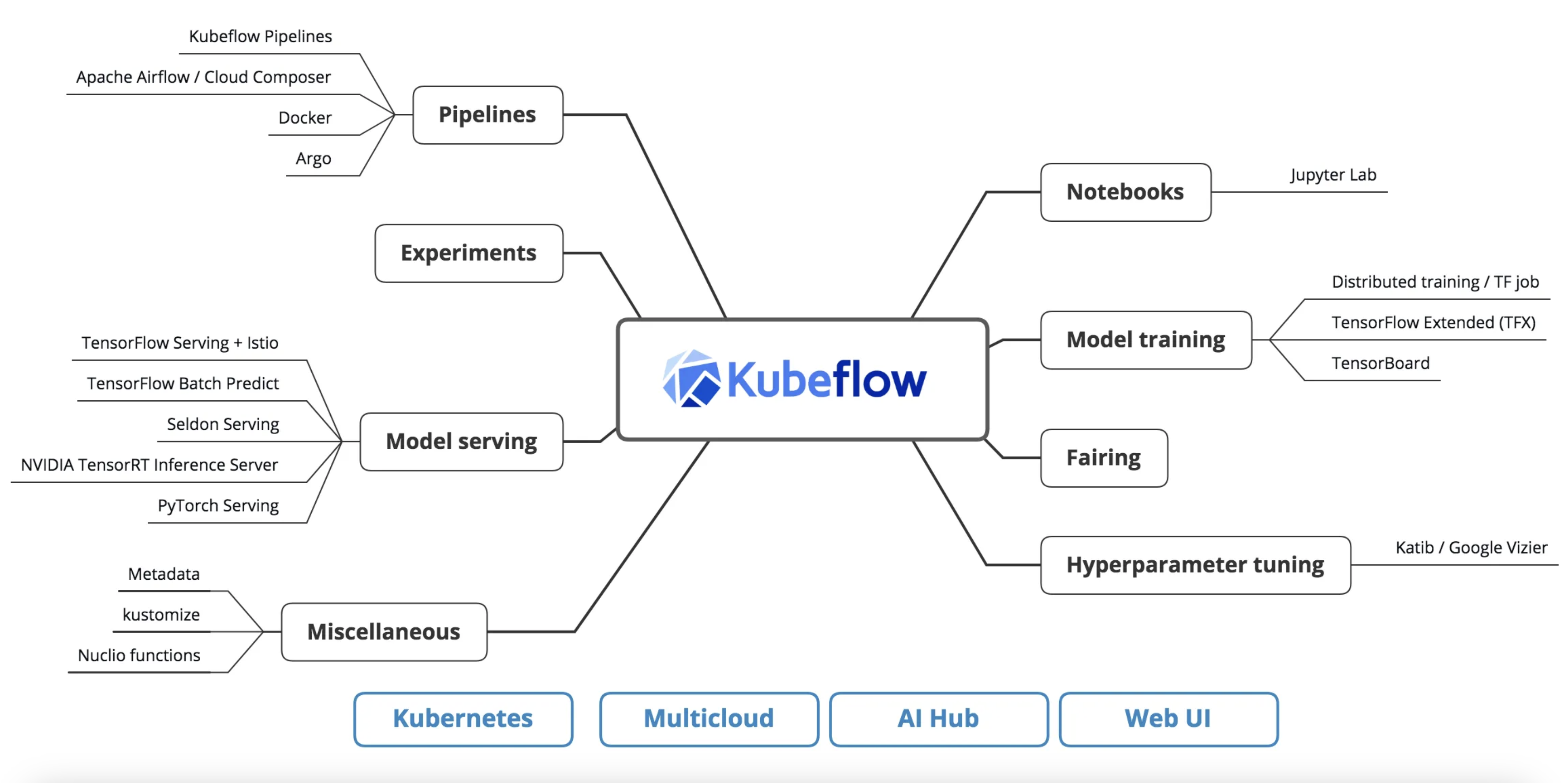
Kubernetes and MLOps: Kubeflow
I have a full blog post centered around Kubeflow, but wanted to briefly mention it here; as it is an important MLOPs tool for certain scenarios and use cases. If interested in more details regarding Kubeflow, see my blog post Kubeflow: The Power of Machine Learning and Kubernetes.
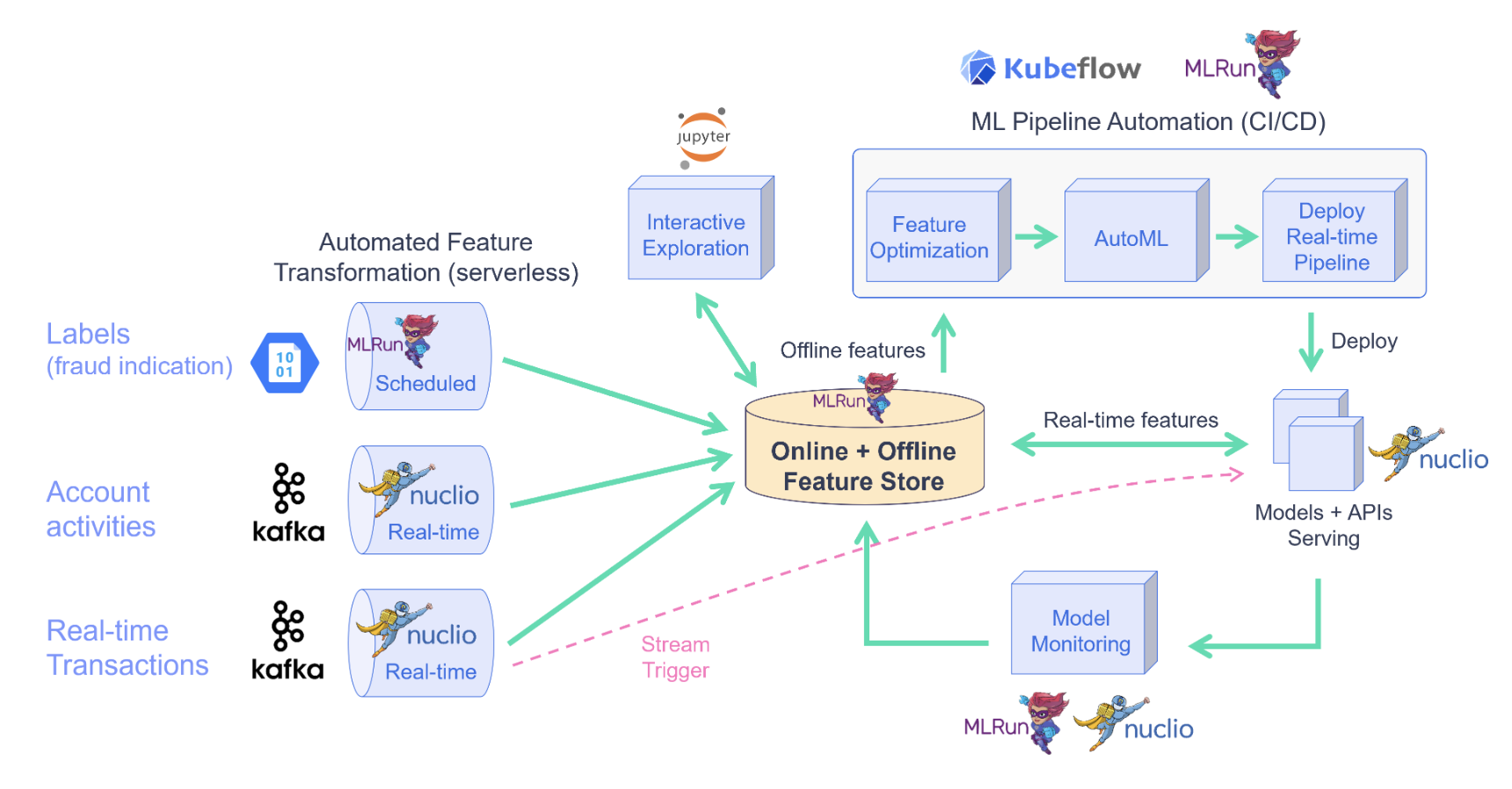
Machine learning or model development essentially follows the path data -> information -> knowledge -> insight. Model development life cycle (MDLC) is a term commonly used to describe the flow between training and inference. Kubeflow is a collection of cloud native tools for all of the stages of MDLC. (Data exploration, feature preparation, model training/tuning, model serving, model testing, and model versioning). Kubeflow also has tooling that allows these traditionally separate tools to work seamlessly together. An important part of this tooling is the pipeline system which allows users to build integrated end-to-end pipelines that connect all components of their MDLC. Kubeflow provides a unified system leveraging Kubernetes for containerization and capability for the portability and repeatability of its pipelines.
Written: November 17, 2024