Generative AI
Generative artificial intelligence (AI) is a type of deep learning model that can produce text, images, computer code, and audiovisual content in response to prompts. Generative AI models are trained on vast quantities of raw data — generally, the same kinds of data they are built to produce. From that data, they learn to form responses, when given arbitrary inputs, that are statistically likely to be relevant for those inputs.
For example, some generative AI models are trained on large amounts of text, in order to be able to respond to written prompts in a seemingly organic and original manner. In simpler terms, generative AI can react to requests much like human artists or authors, but more quickly. Whether the content these models generate can be considered "new" or "original" is up for debate, but in many cases they can match or exceed certain human creative abilities.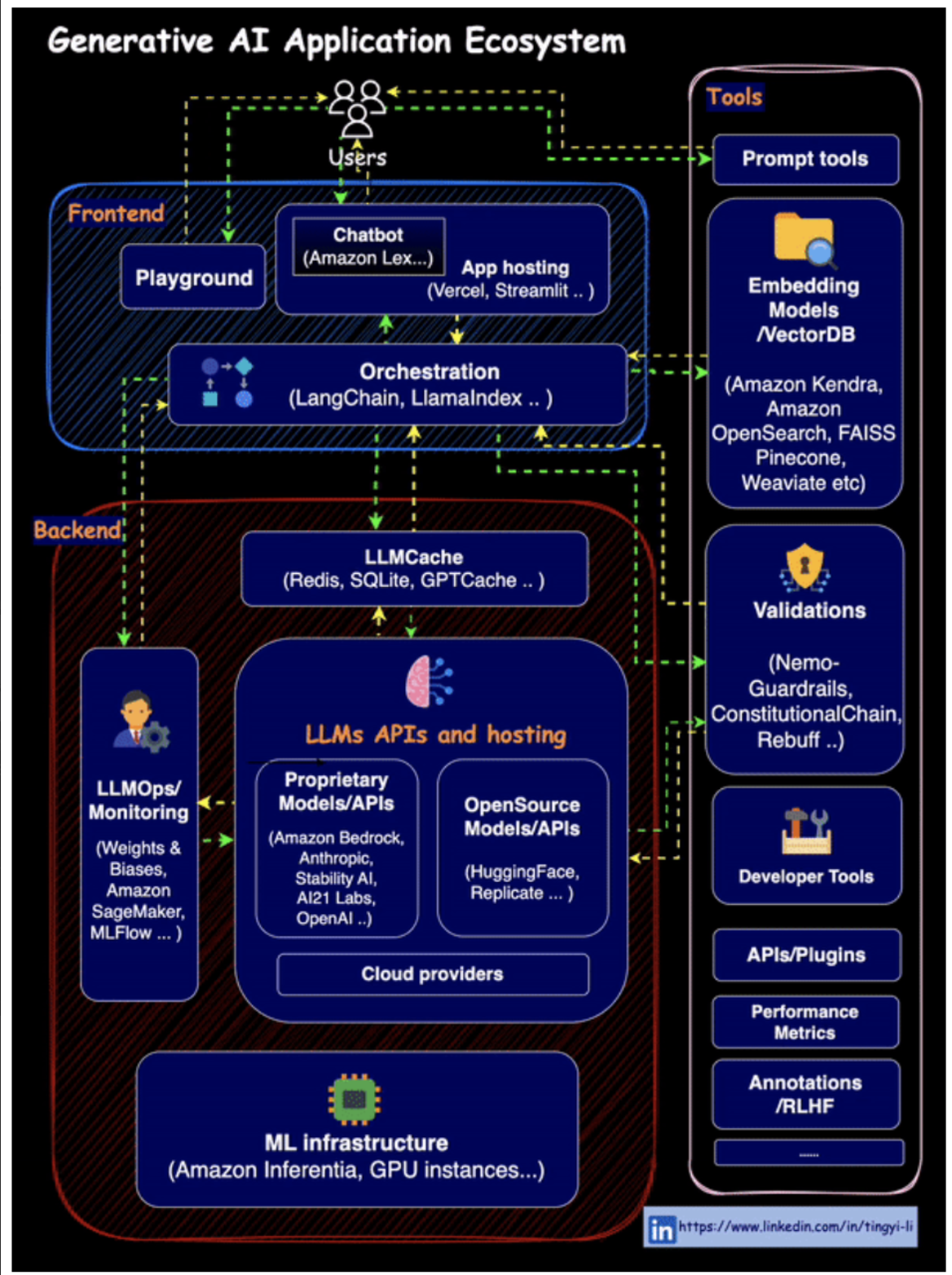
Vector Database
A vector database is a collection of data stored as mathematical representations. Vector databases make it easier for machine learning models to remember previous inputs, allowing machine learning to be used to power search, recommendations, and text generation use-cases. Data can be identified based on similarity metrics instead of exact matches, making it possible for a computer model to understand data contextually.
When one visits a shoe store, a salesperson may suggest shoes that are similar to the pair one prefers. Likewise, when shopping in an e-commerce store, the store may suggest similar items under a header like "Customers also bought..." Vector databases enable machine learning models to identify similar objects, just as the salesperson can find comparable shoes and the ecommerce store can suggest related products.
To summarize, vector databases make it possible for computer programs to draw comparisons, identify relationships, and understand context. This enables the creation of advanced artificial intelligence (AI) programs like large language models (LLMs).
What is a Vector?
A vector is an array of numerical values that expresses the location of a floating point along several dimensions. In more everyday language, a vector is a list of numbers, like: {12, 13, 19, 8, 9}. These numbers indicate a location within a space, just as a row and column number indicates a certain cell in a spreadsheet (e.g. "B7").
Each vector in a Vector Database corresponds to an object or item, whether that is a word, an image, a video, a movie, a document, or any other piece of data. These vectors are likely to be lengthy and complex, expressing the location of each object along dozens or even hundreds of dimensions.- Machine learning and deep learning: The ability to connect relevant items of information makes it possible to construct machine learning (and deep learning) models that can do complex cognitive tasks.
- Large language models (LLMs) and generative AI: LLMs, like that on which ChatGPT and Bard are built, rely on the contextual analysis of text made possible by vector databases. By associating words, sentences, and ideas with each other, LLMs can understand natural human language and even generate text.
LLM - Large Language Model
A large language model (LLM) is a type of artificial intelligence (AI) program that can recognize and generate text, among other tasks. LLMs are trained on huge sets of data — hence the name "large." LLMs are built on machine learning: specifically, a type of neural network called a transformer model. In simpler terms, an LLM is a computer program that has been fed enough examples to be able to recognize and interpret human language or other types of complex data. Many LLMs are trained on data that has been gathered from the Internet — thousands or millions of gigabytes' worth of text. But the quality of the samples impacts how well LLMs will learn natural language, so an LLM's programmers may use a more curated data set.
LLMs use a type of machine learning called deep learning in order to understand how characters, words, and sentences function together. Deep learning involves the probabilistic analysis of unstructured data, which eventually enables the deep learning model to recognize distinctions between pieces of content without human intervention. LLMs are then further trained via tuning: they are fine-tuned or prompt-tuned to the particular task that the programmer wants them to do, such as interpreting questions and generating responses, or translating text from one language to another.
How LLMs Work
At a basic level, LLMs are built on machine learning. Machine learning is a subset of AI, and it refers to the practice of feeding a program large amounts of data in order to train the program how to identify features of that data without human intervention. LLMs use a type of machine learning called deep learning. Deep learning models can essentially train themselves to recognize distinctions without human intervention, although some human fine-tuning is typically necessary. Deep learning uses probability in order to "learn."- For instance, in the sentence "The quick brown fox jumped over the lazy dog," the letters "e" and "o" are the most common, appearing four times each.
- From this, a deep learning model could conclude (correctly) that these characters are among the most likely to appear in English-language text.
Transfer Learning
Transfer learning is a machine learning technique in which a model developed for a given task is reused as the starting point for a model on a second task. You take a pre-trained model (a model trained on a large data set) and adapt it for a different (but related) problem. Transfer learning is useful when you have a small data set for the problem you are interested in solving, but also have access to a much larger, related data set. Several different types of transfer learning are possible:
- Feature Extraction: The pretrained model act as a feature extractor. You remove the output layer and add new layers that are specific to your task.
- Fine-Tuning: You not only replace the output layer, but also continue to train the entire network, sometimes at a lower learning rate, to allow the pretrained model to adapt to the new task.
- Task Specific Models: Sometimes, certain layers of pretrained model may be replaced or adapted to make the model better suited to the new task.
Deep Learning
Deep learning is a type of machine learning that can recognize complex patterns and make associations in a similar way to humans. Its abilities can range from identifying items in a photo or recognizing a voice to driving a car or creating an illustration. Essentially, a deep learning model is a computer program that can exhibit intelligence, thanks to its complex and sophisticated approach to processing data.
Deep learning is one kind of artificial intelligence (AI), and it is core to how many AI services and models function. Large language models (LLMs) such as ChatGPT, Bard, and Bing Chat, and image generators such as Midjourney and DALL-E, rely on deep learning to learn language and context, and to produce realistic responses. reductive AI models use deep learning to gain conclusions from sprawling collections of historical data.
Natural Language Processing (NLP)
A type of artificial intelligence (AI) that allows computers to interpret human language. NLP is often built on deep learning (via machine learning), a type of machine learning that can process raw data without labels, and also draw on the field of linguistics — the study of the meaning of language. While programming languages are the best way to give computers commands, natural language processing enables computer programs to do a wide variety of both spoken and written tasks with human language. For example, it can help process large data collections of voice recordings and written texts, automate interactions with human users, or interpret user queries. NLP uses machine learning to analyze human-generated content statistically and learn how to interpret it. During the training process, NLP models are fed examples of words and phrases in context, along with their interpretations.
For preprocessing, NLP uses raw text for analysis by a program or machine learning model. NLP preprocessing is necessary to put text into a format that deep learning models can more easily analyze. There are several NLP preprocessing methods that are used together. The main ones are:
- Converting to lowercase: In terms of the meaning of a word, there is little difference between uppercase and lowercase. Therefore, converting all words to lowercase is more efficient because many computer programs are case-sensitive and might treat uppercase versions of words differently unnecessarily.
- Stemming: This reduces words down to their root or "stem" by removing endings like "-ing" or "-tion".
- Lemmatization: This NLP technique reduces words to the primary form that could be found in a dictionary.
- Tokenization: This breaks text into smaller pieces that indicate meaning. The pieces are usually composed of phrases, individual words, or subwords.
- Stop word removal: Many words are important for grammar or for clarity when people talk amongst themselves, but do not add a great deal of meaning to a sentence and are not necessary for processing language in a computer program. Such words are called "stop words" in the context of NLP, and stop word removal takes them out of text. As an example, in the sentence "I went to college for four years," the words "to" and "for" are essential for the sentence to sound intelligible to human ears, but not necessary for carrying meaning. The stop-word-removal version could be: "I went college four years."
Because they have such a broad range of uses, LLMs require far more data and training than NLP models.
Some examples of NLP include:- Machine translation: Uses AI to automatically translate text from one language to another.
- Named-entity recognition: Identifies unique names for people, places, events, companies, and more.
- Sentiment analysis: Analyzes text to determine the emotion conveyed, such as positive, negative, or neutral.
- Speech recognition: Uses NLP to allow computers to simulate human interaction. For example, Google Now, Alexa, and Siri can recognize spoken commands and perform actions
- Other NLP techniques include:
- Natural language understanding (NLU)
- Natural language generation (NLG)
- Natural language interaction (NLI)
- Multimodal NLP, which integrates text with other modalities like images and videos
- Continual learning, which allows NLP models to adapt and learn from new data sources
- Text-to-speech (TTS) and speech-to-text (STT) systems
- Question-answering software
Embeddings
Embeddings in AI refer to the conversion of discrete variables into continuous vectors of fixed dimensions and lower dimensional space. The idea is to map similar items or words close to each other in that vector space thereby capturing the semantic or functional relationships among them. In addition to recommendation systems and other machine learning tasks, Embeddings can also be used for other types of data such as graph data, where nodes can be embedded into continuous vectors. More simply put, Embeddings are vectors generated by neural networks. A typical vector database for a deep learning model is composed of embeddings. Once a neural network is properly fine-tuned, it can generate embeddings on its own so that they do not have to be created manually, and these embeddings can then be used for similarity searches, contextual analysis, generative AI, and so on.
Advantages
Querying a machine learning model on its own, without a vector database, is neither fast nor cost-effective. Machine learning models cannot remember anything beyond what they were trained on. They have to be the context every single time (which is how many simple chatbots work). Passing the context of a query to the model every time is very slow, as it is likely to be a lot of data; and expensive, as data has to move around, and computing power has to be expended repeatedly having the model parse the same data. And in practice, most machine learning APIs are likely constrained in how much data they can accept at once anyway. This is where a vector database comes in handy: a dataset goes through the model only once (or periodically as it changes), and the model's embeddings of that data are stored in a vector database.- This saves a tremendous amount of processing time. It makes building user-facing applications around semantic search, classification, and anomaly detection possible, because results come back within tens of milliseconds, without waiting for the model to crunch through the whole data set.
- For queries, developers ask the machine learning model for a representation (embedding) of just that query. Then the embedding can be passed to the vector database, and it can return similar embeddings — which have already been run through the model.
- Those embeddings can then be mapped back to their original content: whether that is a URL for a page, a link to an image, or product SKUs.
Neural Network
A neural network, or artificial neural network, is a type of computing architecture that is based on a model of how a human brain functions — hence the name "neural." Neural networks are made up of a collection of processing units called "nodes."
These nodes pass data to each other, just like how in a brain, neurons pass electrical impulses to each other. Neural networks are used in machine learning, which refers to a category of computer programs that learn without definite instructions. Specifically, neural networks are used in deep learning — an advanced type of machine learning that can draw conclusions from unlabeled data without human intervention. For instance, a deep learning model built on a neural network and fed sufficient training data could be able to identify items in a photo it has never seen before. Neural networks make many types of artificial intelligence (AI) possible. Large language models (LLMs) such as ChatGPT, AI image generators like DALL-E, and predictive AI models all rely to some extent on neural networks. There is no limit on how many nodes and layers a neural network can have, and these nodes can interact in almost any way. Because of this, the list of types of neural networks is ever-expanding. But, they can roughly be sorted into these categories:- Shallow neural networks usually have only one hidden layer
- Deep neural networks have multiple hidden layers
- Perceptron neural networks are simple, shallow networks with an input layer and an output layer.
- Multilayer perceptron neural networks add complexity to perceptron networks, and include a hidden layer.
- Feed-forward neural networks only allow their nodes to pass information to a forward node.
- Recurrent neural networks can go backwards, allowing the output from some nodes to impact the input of preceding nodes.
- Modular neural networks combine two or more neural networks in order to arrive at the output.
- Radial basis function neural network nodes use a specific kind of mathematical function called a radial basis function.
- Liquid state machine neural networks feature nodes that are randomly connected to each other.
- Residual neural networks allow data to skip ahead via a process called identity mapping, combining the output from early layers with the output of later layers.
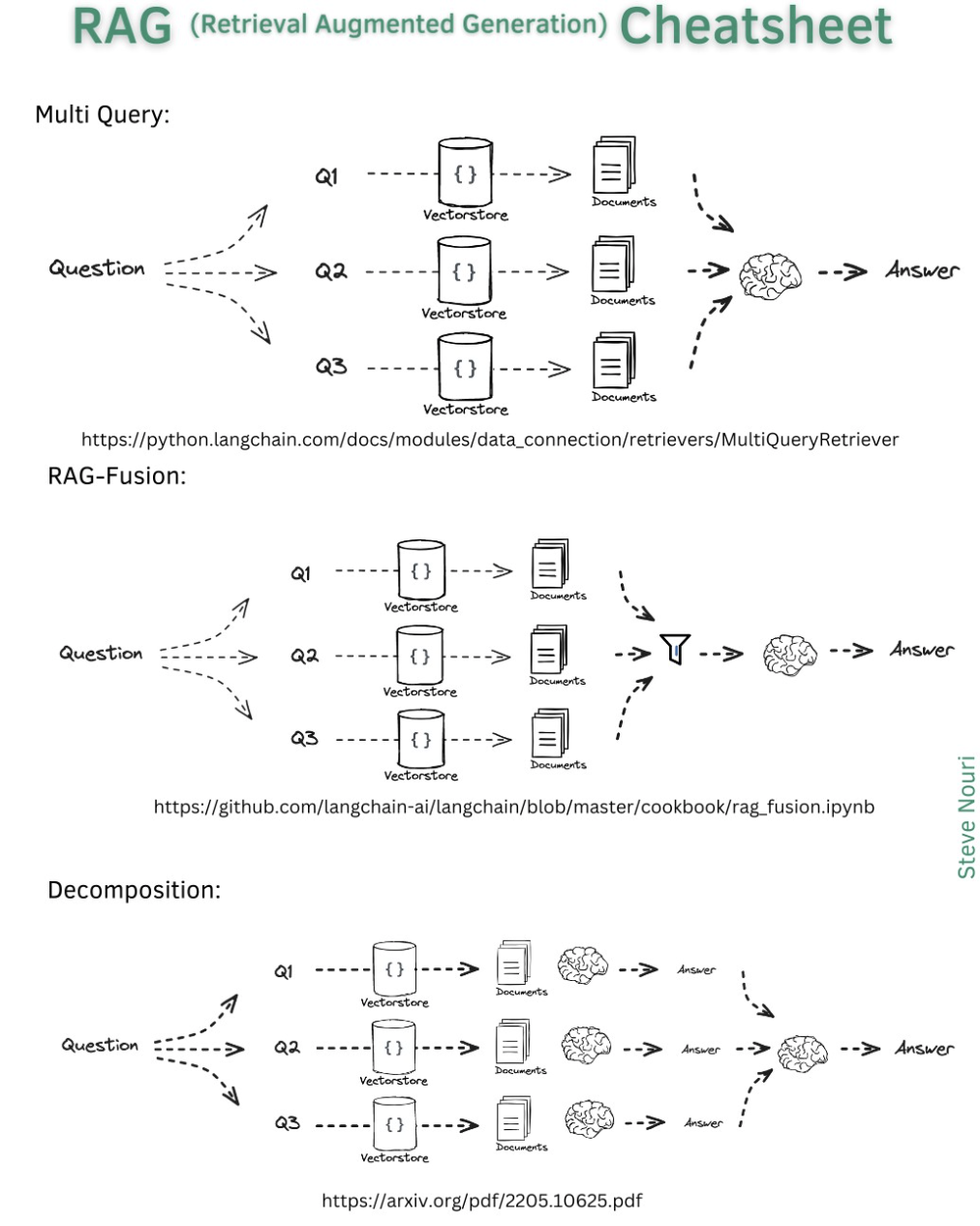
RAG - Retrieval Augmented Generation
Retrieval-Augmented Generation (RAG) is an innovative approach in natural language processing (NLP) that integrates retrieval mechanisms with generative models to enhance text generation. By incorporating external knowledge from pre-existing sources, RAG addresses the challenge of generating contextually relevant and informative text. This integration enables RAG to overcome the limitations of traditional generative models by ensuring that the generated text is grounded in factual information and context. RAG aims to solve the problem of information overload by efficiently retrieving and incorporating only the most relevant information into the generated text, leading to improved coherence and accuracy. Overall, RAG represents a significant advancement in NLP, offering a more robust and contextually aware approach to text generation.
 Examples for application of these technique includes for instance customer service chat bots that use a knowledge base to answer support requests.
In the context of Retrieval-Augmented Generation (RAG), knowledge seeding involves incorporating external information from pre-existing sources into the generative process, while querying refers to the mechanism of retrieving relevant knowledge from these sources to inform the generation of coherent and contextually accurate text.
Examples for application of these technique includes for instance customer service chat bots that use a knowledge base to answer support requests.
In the context of Retrieval-Augmented Generation (RAG), knowledge seeding involves incorporating external information from pre-existing sources into the generative process, while querying refers to the mechanism of retrieving relevant knowledge from these sources to inform the generation of coherent and contextually accurate text.
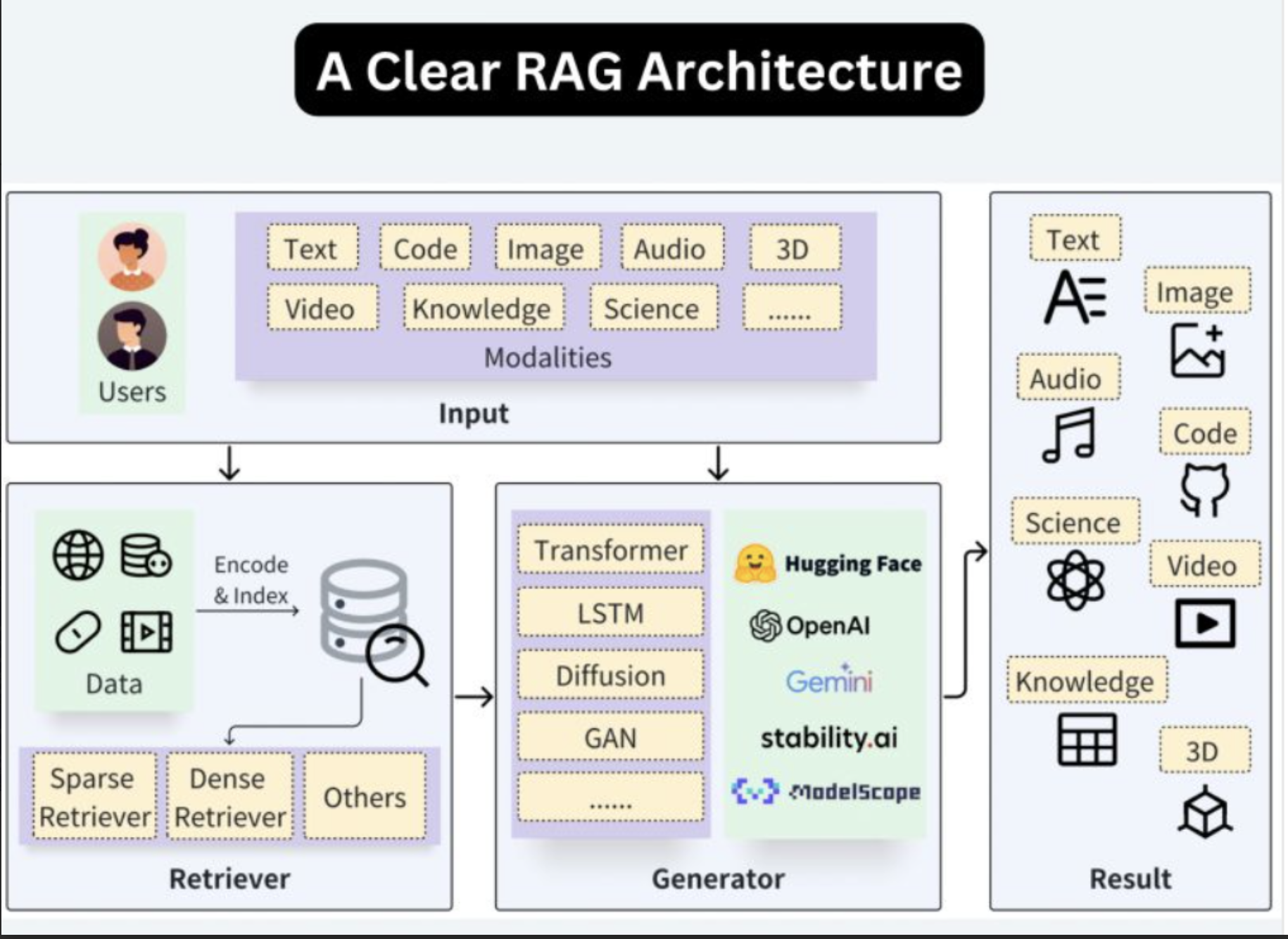
RAG Architecture / Cheatsheets
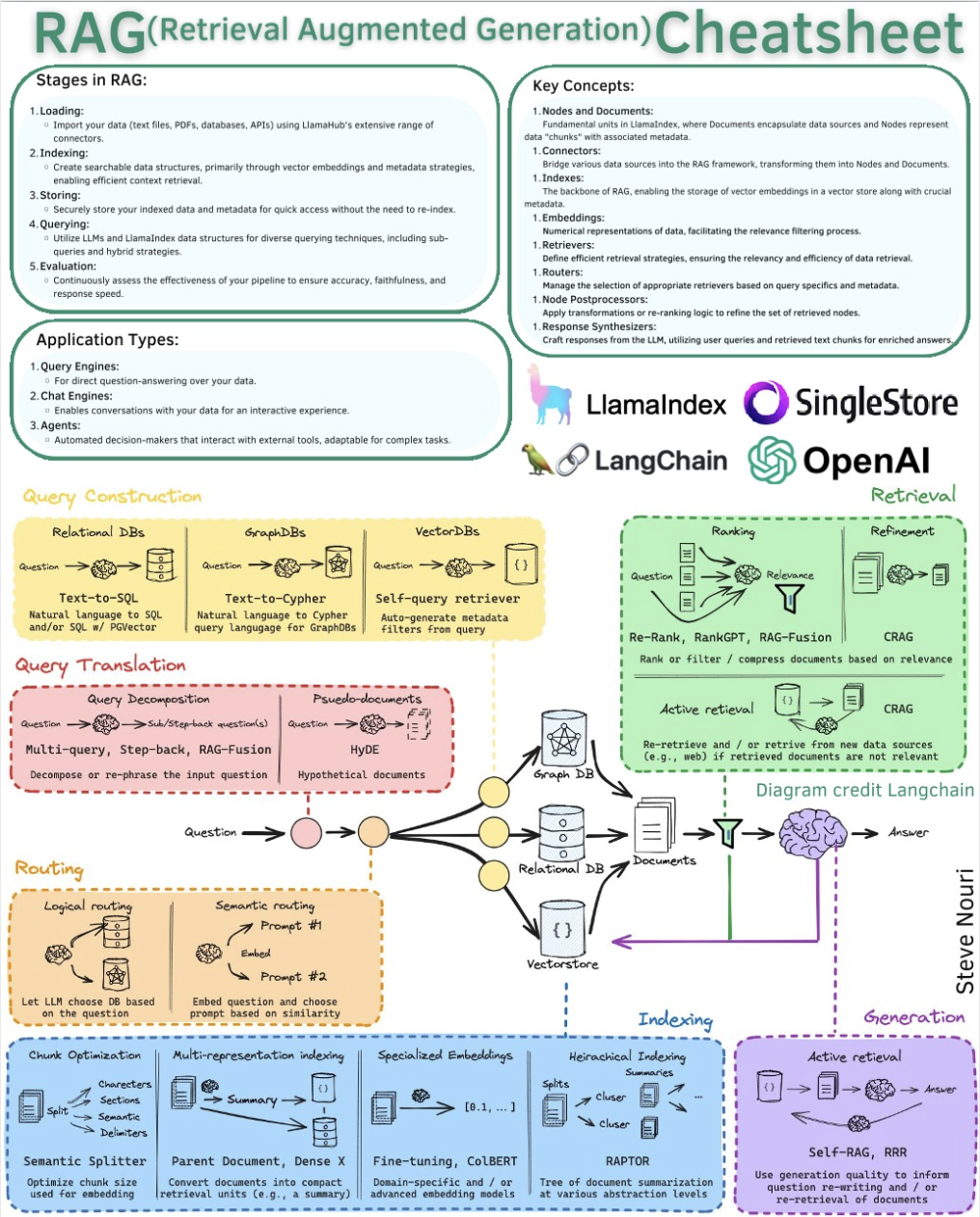
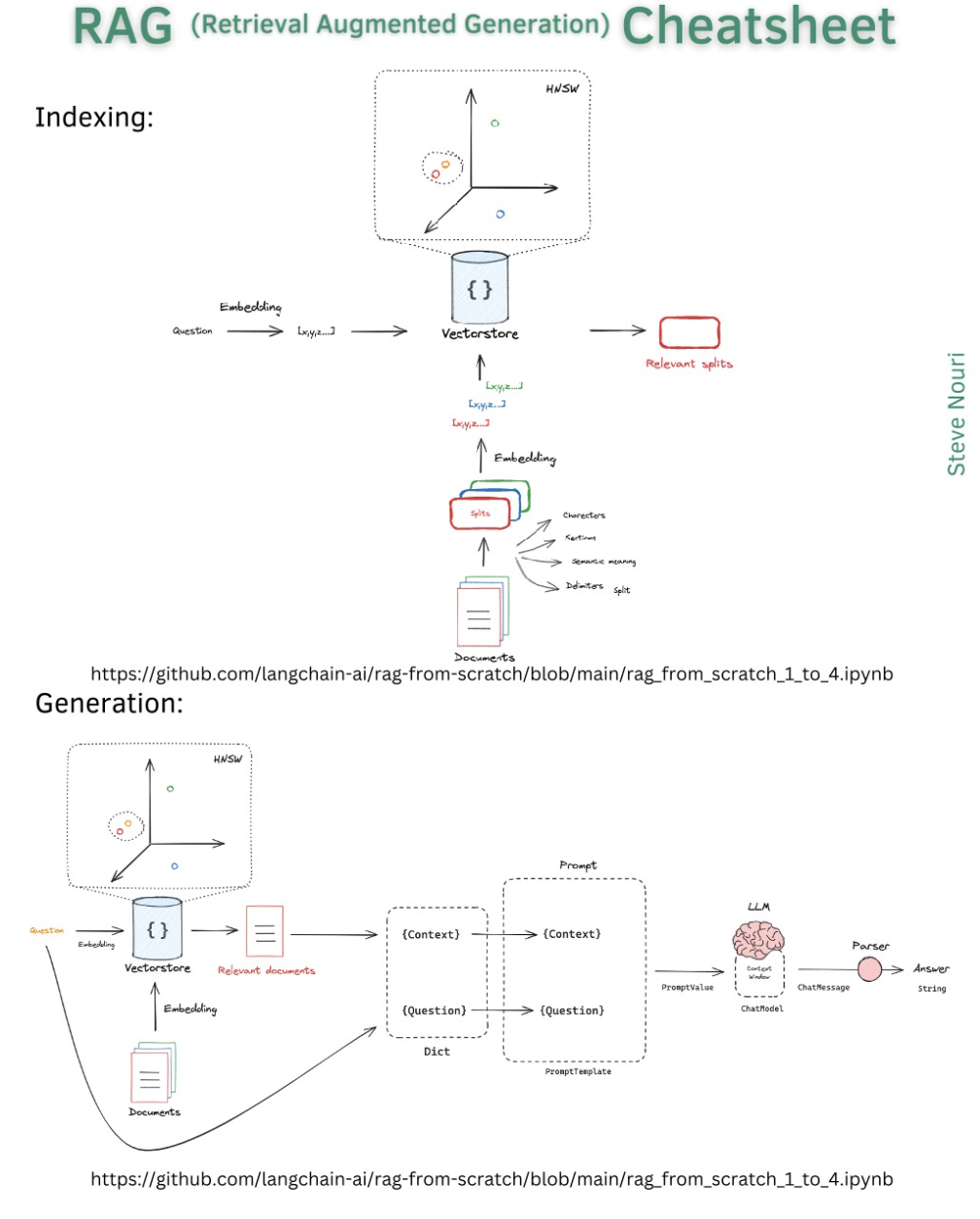
AI and DevOps - MLOps / AIOps
Even the most advanced deep learning models require access to massive data sets to obtain accurate results. One fundamental requirement to solve in MLOps is Data Egress. Cloud storage is ideal for saving these big data sets, since cloud computing is almost infinitely scalable. However, accessing that data often results in egress fees: charges from cloud providers for transferring data from storage.
Another essential requisite for an MLOps engineer is configuring and allocating the necessary and relevant Compute power and infrastructure. Machine learning, and especially deep learning, requires a lot of computational power. Machine learning models require the use of specialized, and expensive, hardware or cloud services — for instance, multiple fast, GPU-powered servers (A GPU or graphical processing unit is more powerful than a traditional CPU), or even TPU.A Cloud TPU is an AI accelerator application-specific integrated circuit (ASIC) developed by Google specifically for neural network machine learning, particularly using Google's own TensorFlow software. Cloud TPU is the custom-designed machine learning ASIC that powers Google products like Translate, Photos, Search, Assistant, and Gmail.
- ASIC - An application-specific integrated circuit is an integrated circuit (IC) chip customized for a particular use, rather than intended for general-purpose use, such as a chip designed to run in a digital voice recorder or a high-efficiency video codec. Application-specific standard product chips are intermediate between ASICs and industry standard integrated circuits like the 7400 series or the 4000 series.
At its core, AIOps is about leveraging the power of AI to automatically collect, analyze, and act upon the vast amounts of data generated by IT systems. This data includes logs, metrics, events, and traces from applications, infrastructure, and networks as well as external data sources, such as user feedback and business metrics. By applying advanced machine learning algorithms and analytics techniques to this data, platforms can identify patterns, anomalies, and insights that would be impossible for human operators to detect. AIOps also incorporates automation and orchestration capabilities. Allowing it to detect issues, automatically trigger remediation actions, and optimize system configurations in real time. This closed loop approach to operations enables faster incident response, reduced downtime, and improved service quality.
Some benefits of implementing AIOps include:
- Improved operational efficiency and productivity
- Faster issue detection and resolution
- Proactive problem prevention
- Better user experience and service quality
- Cost savings and ROI
AIOps platforms and techniques have broad applicability across various industries and address common challenges such as complexity, scalability, and agility. However, to give a few examples of AI solutions and use cases, some industry specific applications could be for example:
- Fraud Detection
- Risk Management
- Compliance Monitoring
- Patient Monitoring
- Clinical Decision Support
- Remote Patient Management
Written: April 14, 2024